The DevOps Ways @ DOH19
Il 26 ottobre a Parma si è tenuta la conferenza DevOps Heroes e, anche quest’anno, ero presente come speaker! E’ sempre un piacere partecipare a questa conferenza! Devo fare nuovamente i complimenti ad Alessandro Alpi perché riesce a mettere tutti a proprio agio, è premuroso e omnipresente, anche se la sua presenza quasi non si nota.
Il mio intervento, dal titolo The DevOps Way, vuole raccontare il mio viaggio nel mondo DevOps e di tutte quelle volte che ho creduto di essere un provetto DevOps. In realtà ero molto lontano proprio da quello spirito DevOps, che solo ora credo di aver compreso! Quasi certamente scoprirò di sbagliare ancora tutto e che DevOps è qualcosa di diverso da quello che oggi penso che sia.
Potete trovare le slides della mia presentazione a questo link, ma esse hanno poca utilità senza la mia voce che ve le racconta, quindi provo a scrivere una serie di articoli per raccontarvi la mia esperienza!
Incipit
Dieci anni fa avevo un pipeline di build, un sistema di deploy automatico, un log collector e pensavo di essere DevOps.
In realtà ero molto distante dall’esserlo!
Non avevo capito nulla di DevOps!
2011-2012 - inizio del percorso
Facevo parte di un team multi-funzionale che sviluppava un’applicazione web. Il front-end era modulare a plugin, essi sfruttavano alcune librerie condivise e vi era una parte core che permetteva l’avvio dell’applicazione. Il core gestiva il caricamento dei plugin e offriva dei servizi come il message bus utilizzato dai componenti per comunicare tra di loro e con il back-end. La parte back-end utilizzava un’architettura a micro-servizi e anch’essi usavano delle librerie condivise e un SDK che offriva, in modo semplice, le funzionalità base per il funzionamento della piattaforma, come l’accesso al message bus lato back-end e la gestione della comunicazione con il front-end tramite websockets.
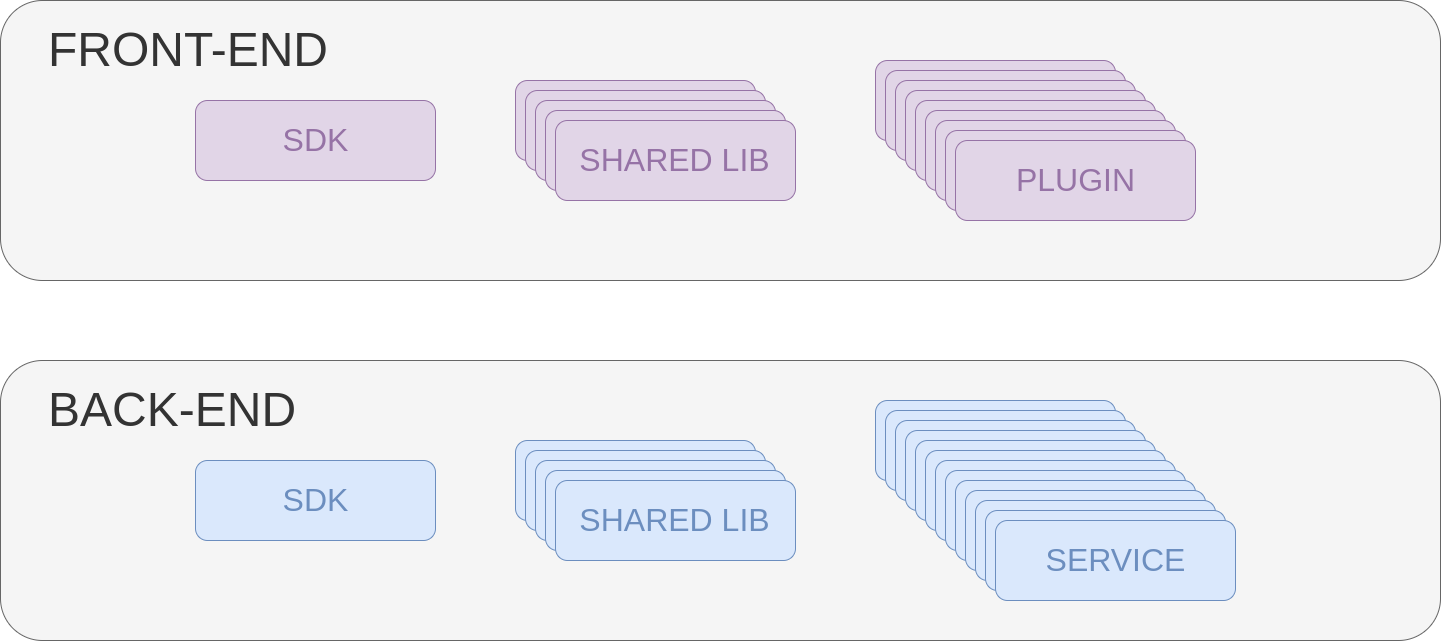
Compilare e testare manualmente i componenti era una cosa abbastanza complessa a cuasa del dependency tree da rispettare e che richiedeva parecchio tempo visto la presenta di tanti componenti. La build era un’operazione parecchio noiosa e ripetivia; inoltre, facendo queste operazioni localmente il team stesso aveva poca visibilità sullo stato dei test e di eventuali errori di compilazione dovuti a modifiche nei componenti upstream. La situazione peggiorava con l’aumentare dei plugin lato front-end, dei micro-servizi back-end e delle librerie condivise e stava per diventare un problema. Beh, la soluzione adottata è stata abbastanza ovvia… automatizzazione delle build e degli unit test.
Il team lavorava usando la metodologia scrum e ogni 2 settimane era necessario effettuare il rilascio del lavoro svolto. Le procedure manuali di rilascio erano molto semplici! Il deploy veniva effettuato su un cloud ti tipo platform e bastava eseguire un comando per fare il deploy di un singolo servizio, ovviamente con l’aumentare del numero dei servizi aumentava il tempo necessario al deploy e questo a tendere sarebbe diventato un problema. In realtà, il problema dei deploy manuali si è verificato molto prima del previsto, perché si è reso necessario creare dei test d’integrazione per il back-end e dei test e2e per verificare che tutto il sistema funzionasse correttamente. Visto le esigenze di eseguire i test su l’ambiente in esecuzione abbiamo automatizzato dei deploy e ci siamo subito resi conto che avremmo potuto fare molto di più!

Dovevamo gestire 3 scenari differenti per il deploy: cloud pubblico (servizio fornito da un provider esterno), cloud privato (installazione di unàistanza del cloud on-premise) e cloud ibrido. La procedura di deploy dell’applicazione non dipendeva dallo scenario cloud in cui andava installatae questo ci ha aiutato a mantenere le automazioni semplici, ma in alcuni casi avremmo dovuto installare anche il cloud stesso! Avremmo dovuto testare anche l’installazione del cloud ed essere certi che la sua installazione fosse ripetibile, consistente e funzionante! Queste motivazioni ci ha spinto nuovamente verso l’automatizzazione e abbiamo automatizzato il deploy della nostra applicazione e quello del cloud stesso. Una volta create queste automazioni abbiamo potuto eseguire in modo molto strutturato gli integration test e gli e2e test e abbiamo anche aggiunto dei test per verificare che l’automazione stessa funzionasse correttamente!
Oltre alla parte necessaria a portare il codice in produzione abbiamo lavorato anche sul rendere l’applicazione debuggabile in maniera più semplice e rapida. Originariamente i log di ogni istanza di un mirco-servizio erano locali all’istanza stessa ed era necessario collegarsi a ogni singolo micro-servizio per accedere ai log; inoltre, i log venivano eliminati ogni volta che un micro-servizio si fermava, anche come conseguenza di un crash! Un altro dei problemi che avevamo in fase di debug era quello di comprendere cosa accadesse a un messaggio: attraverso quali componenti era passato, quanto tempo è stato necessario per processarlo e ci sono stati degli erorri. La risposta a queste necessità l’abbiamo trovata creando un servizio di log collector e aggiungendo le informazioni di tracking nel messaggio stesso.
Il sistema di log collector non era altro che un ulteriore micro-servizio da noi sviluppato, con lo scopo di raccogliere i log dagli altri servizi e permetterci di consultarli in modo semplice. Questo servizio è stato creato con 2 caratteristiche: funzionare senza alcuna conoscenza degli altri servizi (questo permette la scalabilità del sistema e la sua autoconfigurazione) e la possibilità di aggregare e filtrare i log per intervallo temporale o per micro-servizio.
Il sistema di message tracking non è un componente (o servizio) aggiuntivo, ma fu implementato direttamente all’interno del SDK. Ogni volta che un messaggio era preso in carico da un componente o veniva pubblicato sul message bus, veniva aggiunto un record all’interno del messaggio con alcune informazioni. Il formato del messaggio era JSON e le informazioni aggiunte erano: nome del componente in cui è passatto il messaggio, timestamp in cui è stato preso in carico e timestamp in cui è stato ri-pubblicato sul bus (equivalente al termine del’elaborazione), ed eventuali codici degli errori occursi durante l’elaborazione e da usare come filtro nelle query al message collector.
![]()
Sopra trovate un esempio di come erano inseriti i dati di trace all’interno dei messaggi.
Conclusioni - pt.1
Abbiamo adottato alcune tecniche che vengono tipicamente “pubblicizzate” come pratiche DevOps:
- Continuous Integration
- Build & Test Automation
- (near) Continuous Delivery (2 deploy in staging al giorno per eseguire e2e test)
- Log Collector
- Telemetry (tramite tracking dei messaggi)
Raccontata in questo modo, sembra che avevo proprio ragione a pensare di essere DevOps.
In realtà ero molto distante dall’esserlo! Non avevo capito nulla di DevOps!
Ma perché?
Lo scoprirete nella seconda parte di questo articolo, tra qualche giorno!